How is resolution computed¶
[1]:
import numpy as np
import matplotlib.pyplot as plt
from ctaplot.ana import resolution
Normal distribution¶
For a nomal distribution,  corresponds to the 68 percentile of the distribution
corresponds to the 68 percentile of the distribution
corresponds to the 68 percentile of the distributionSee the 68–95–99.7 rule
[2]:
loc = 10
scale = 3
X = np.random.normal(size=1000000, scale=scale, loc=loc)
plt.hist(np.abs(X - loc), bins=80, density=True)
sig_68 = np.percentile(np.abs(X - loc), 68.27)
sig_95 = np.percentile(np.abs(X - loc), 95.45)
sig_99 = np.percentile(np.abs(X - loc), 99.73)
plt.vlines(sig_68, 0, 0.3, label='68%', color='red')
plt.vlines(sig_95, 0, 0.3, label='95%', color='green')
plt.vlines(sig_99, 0, 0.3, label='99%', color='yellow')
plt.ylim(0,0.3)
plt.legend()
print("68th percentile = {:.4f}".format(sig_68))
print("95th percentile = {:.4f}".format(sig_95))
print("99th percentile = {:.4f}".format(sig_99))
assert np.isclose(sig_68, scale, rtol=1e-2)
assert np.isclose(sig_95, 2 * scale, rtol=1e-2)
assert np.isclose(sig_99, 3 * scale, rtol=1e-2)
68th percentile = 3.0010
95th percentile = 5.9976
99th percentile = 8.9889

Resolution¶
The resolution is defined as the 68th percentile of the relative error
err = (reco - simu)/recoHence, if the relative error follows a normal distribution, the resolution is equal to the sigma of the distribution
[3]:
err = np.abs(X - loc)
simu = loc * np.ones(X.shape[0])
plt.hist(err, bins=80)
plt.title('err')
plt.show()

Let’s define
reco in order to have a relative error equals to err.Its resolution is equals to the sigma of the distribution
[4]:
reco = simu / (1 - (X - loc))
res = resolution(simu, reco)
print(res)
assert np.isclose(res[0], scale, rtol=1e-2)
[3.00101448 2.99622303 3.0056059 ]
Error bars¶
Errors bars in resolution plots are given by the confidence interval (by default at 95%, equivalent to 2 sigmas for a normal distribution).
This means that we can be confident at 95% that the resolution values are within the range given by the error bars.
The implementation for percentile confidence interval follows: - http://people.stat.sfu.ca/~cschwarz/Stat-650/Notes/PDF/ChapterPercentiles.pdf
Example with a normal distribution:
[5]:
nbins, bins, patches = plt.hist(X, bins=100, density=True)
ymax = 1.1 * nbins.max()
plt.ylim(0, ymax)
plt.vlines(np.percentile(X, 68.27), 0, ymax, color='red')
plt.show()
print("The true 68th percentile of this distribution is: {:.4f}".format(np.percentile(X, 68.27)))

The true 68th percentile of this distribution is: 11.4245
We can consider this as our underlying (infinite) distribution.
If we take a random sample in this ditribution, the measurement of a percentile will come with a measurement error. We can assess this error by taking multiple random samples and taking the distribution of measured percentile values.
[6]:
n = 1000
p = 0.6827
all_68 = []
for i in range(int(len(X)/n)):
all_68.append(np.percentile(X[i*n:(i+1)*n], p*100))
all_68 = np.array(all_68)
nbins, bins, patches = plt.hist(all_68, density=True);
ymax = 1.1 * nbins.max()
plt.vlines(all_68.mean(), 0, ymax)
plt.vlines(all_68.mean() + all_68.std(), 0, ymax, color='red')
plt.vlines(all_68.mean() - all_68.std(), 0, ymax, color='red')
plt.ylim(0, ymax)
plt.title("Distribution of the measured 68th percentile")
print("Standard deviation = {:.5f}".format(all_68.std()))
Standard deviation = 0.13226

To evaluate directly the confidence interval from a sub-sample of the distribution, one can use the following formulae:


with 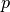 the percentile and
the percentile and  the confidence level desired.
the confidence level desired.
And the confidence interval given by: (![X[R_{low}], X[R_{up}])](../_images/math/678bd1254a19205a652840ed2c3b7b7865464807.png)
The confidence level is given by the cumulative distribution function (
scipy.stats.norm.ppf). Some useful values:- z = 0.47 for a confidence level of 68% - z = 1.645 for a confidence level of 95% - z = 2.33 for a confidence level of 99%
[7]:
# confidence level:
z = 2.33
# sub-sample:
x = X[:n]
rl = int(n * p - z * np.sqrt(n * p * (1-p)))
ru = int(n * p + z * np.sqrt(n * p * (1-p)))
print("Measured percentile: {:.4f}".format(np.percentile(x, p*100)))
print("Confidence interval: ({:.4f}, {:.4f})".format(np.sort(x)[rl], np.sort(x)[ru]))
print("To be compared with: ({:.4f}, {:.4f})".format(all_68.mean()-all_68.std()*3, all_68.mean()+all_68.std()*3))
Measured percentile: 11.3698
Confidence interval: (11.1170, 11.6991)
To be compared with: (11.0254, 11.8190)
Because we are dealing with normal distributions here, we can verify that this corresponds (within statistical margins) to the interval given by twice the standard deviations:
[8]:
err68 = np.abs(all_68 - all_68.mean())
all_68.mean() - 3 * err68.std(), all_68.mean() + 3 * err68.std()
[8]:
(11.183070932430383, 11.661320517902158)
In ctaplot, this is computed by the function percentile_confidence interval:
[9]:
from ctaplot.ana import percentile_confidence_interval
p = 68.27
confidence_level = 0.99
pci = percentile_confidence_interval(x, percentile=p, confidence_level=0.99)
print("68th percentile: {:.3f}".format(np.percentile(x, p)))
print("Interval with a confidence level of {}%: ({:.3f}, {:.3f})".format(confidence_level*100, pci[0], pci[1]))
plt.figure(figsize=(12,7))
nbins, bins, patches = plt.hist(x, bins=100, density=True);
ymax = 1.1 * nbins.max()
plt.vlines(np.percentile(x, 50), 0, ymax, color='black')
plt.vlines(np.percentile(x, p), 0, ymax, color='red')
plt.vlines(pci[0], 0, ymax, linestyles='--', color='red')
plt.vlines(pci[1], 0, ymax, linestyles='--', color='red',)
plt.ylim(0, ymax);
68th percentile: 11.370
Interval with a confidence level of 99.0%: (11.117, 11.699)

Note: The same method could be applied around the median.
In this case, the confidence interval is also given by  for a normal distribution.
for a normal distribution.
for a normal distribution.[10]:
pci = percentile_confidence_interval(X, percentile=50, confidence_level=0.99)
print("Median: {:.5f}".format(np.median(X)))
print("Confidence interval at 99%: {}".format(pci))
print("To be compared with: ({}, {})".format(np.median(X)-3*scale/np.sqrt(len(X)), np.median(X)+3*scale/np.sqrt(len(X))))
Median: 9.99688
Confidence interval at 99%: (9.988429037280191, 10.005916820660993)
To be compared with: (9.987875456368489, 10.00587545636849)